Motivation
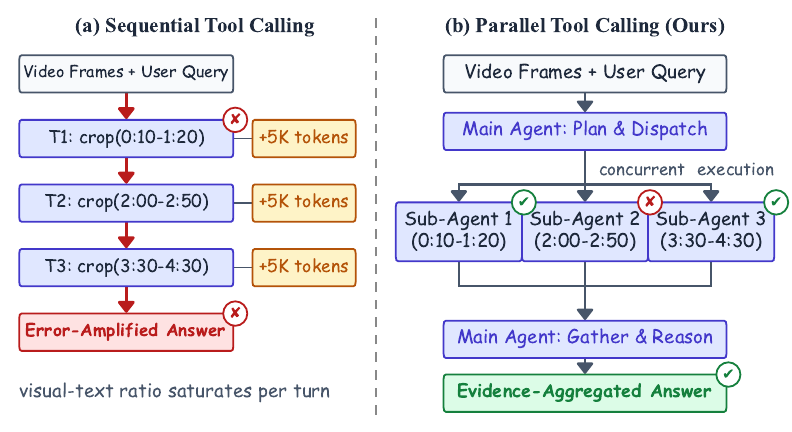
Long-video understanding is increasingly framed as agentic video reasoning: a large multimodal model (LMM) post-trained with reinforcement learning to invoke video-processing tools. Prior native-RL methods, including our earlier LongVT (CVPR 2026), dispatch these tool calls sequentially, one per turn, which is brittle to single mis-localizations, prone to multi-turn context drift, and linear in inference cost.
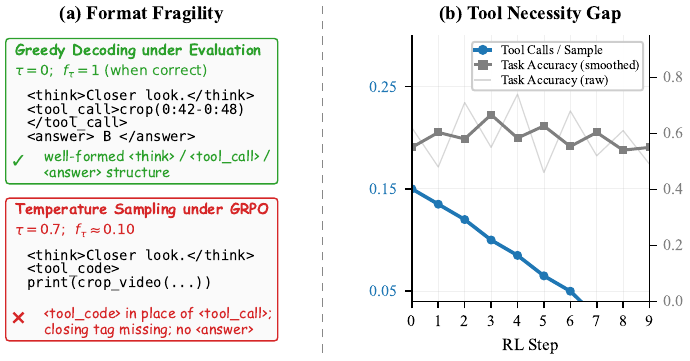
<think>/<tool_call>/<answer>
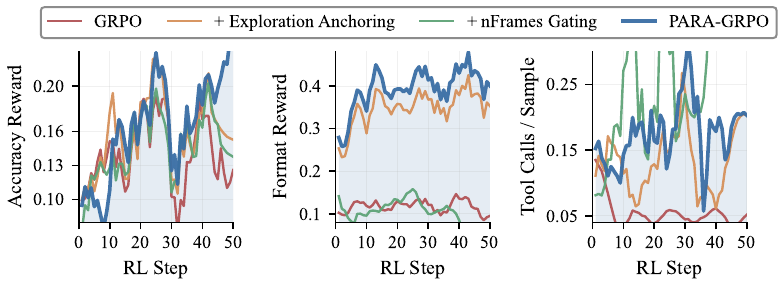
boundary closures decay, leaving rollouts that look almost-parseable but mis-tagged.
Tool Necessity Gap (right): with 64 overview frames many prompts can be answered
without tools, so the GRPO advantage between calling and skipping is near-zero, and the
parallel tool-call rate collapses within a few RL steps while accuracy oscillates flatly.
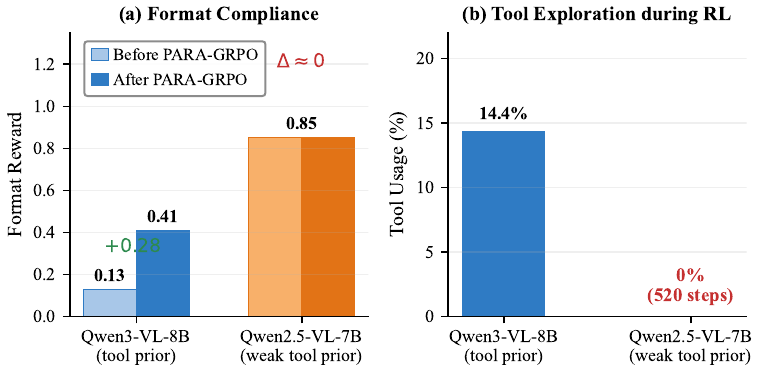
We introduce ParaVT, the first multi-agent end-to-end RL-trained framework for Parallel Video Tool calling: a main agent emits multiple temporal-window crops in a single turn, dispatches them to weight-sharing sub-agents, and aggregates the parallel evidence into a final answer. Applying standard GRPO to ParaVT surfaces two coupled failures driven by the same pretrained tool prior — Format Fragility (the SFT-learned structural tags collapse under temperature sampling) and the Tool Necessity Gap (the skip-tool reward shortcut). We name this trade-off the Tool Prior Paradox and tame it with PARA-GRPO (Parseability-Anchored and Ratio-gAted GRPO): a targeted format reward applied only at the structural-token positions most prone to collapse, paired with a per-prompt frame-budget randomization that lets calling the tool earn measurable RL credit. Across seven evaluation splits spanning six long-video benchmarks plus a temporal-grounding split, ParaVT sets a new open-source 7-8B SOTA on six of the seven, improving over the Qwen3-VL-8B base by +7.9% on average, with PARA-GRPO lifting training-time format compliance from 0.13 to 0.64.